第一部分 设计概述 /Design Introduction
1.1设计目的
本设计中,计划实现对文件的压缩及解压,同时优化压缩中所涉及的信号处理和计算密集型功能,实现对其的加速处理。本设计的最终目标是证明在充分并行化的硬件体系结构 FPGA 上实现该算法时,可以大大提高该算法的速度。我们将首先使用C语言进行代码实现,然后在Vivado HLS中综合实现,并最终在FPGA板(pynq-z2)上进行硬件实现,同时于jupyter notebook中使用python来进行功能验证。
为使代码可综合同时又需要较少的硬件,我们已进行了许多改进,包括以下方面:
-
将所有浮点变量进行量化处理,量化为Q16.16定点,以简化算术运算。与定点相反,浮点型变量需要更多的硬件来执行某些操作。
-
将余弦矩阵实现为8×8查找表,从而消除了对昂贵的CORDIC引擎的需求。
-
在顶层封装时选用AXILITE接口,用于将文件从处理器传输给FPGA并读回。这是PS端和PL端进行数据传输所必须的功能。
-
在各个功能函数分别进行流水线化,展开循环和内联功能,以最大程度地减少延迟并最大程度地提高吞吐量。
1.2 掌握技能
在本项目中,学习到了如下:
-
学习gzip的文件格式,及deflate压缩算法。能够使用deflate算法对文件进行压缩处理,同时将其封装为gzip型文件。 -
学习了hls和python语言的使用。能够通过hls进行相关的IP核开发,同时能够使用python语言来对pynq-z2进行调试。 -
学习了vivado的使用核功能实现。能够灵活利用HLS和vivado来进行功能开发。
1.3 应用方向
随着大数据时代来临,大量信息需要通过互联网进行传输,占用的网络资源急剧增加,给网络传输带来极大的压力。数据压缩技术能够节约数据存储空间、传输时间和带宽,从而缓解传输压力。无损压缩 Gzip 是目前最常用的一种压缩工具,被广泛应用在网络资料的下载和数据备份等领域。其中开源代码 zlib 是 Gzip 算法最著名的实现版本,但因其算法本身计算量较大,导致压缩的数据吞吐率较低。
FPGA 在数据处理速度上有着通用处理器无法比拟的巨大优势,能够大大提升Gzip的处理速度,减小CPU的开销。
1.4 团队分工
李佩琦 负责hls和vivado实现,同时使用python进行功能验证。
冯一飞 负责资料查找,同时负责协助李佩琦进行功能实现和功能测试。
1.5 作品展示
整体功能已经实现,能够在pynq z2上通过gzip压缩方式对txt文件或大段字符串进行压缩。具体展示如图1,左侧是在hls仿真是产生的结果,右侧是通过jupyter notebook在pynq z2上进行调试的结果,两者是一致的,压缩功能能够正常运行。图2是jupyter notebook上部分python代码。
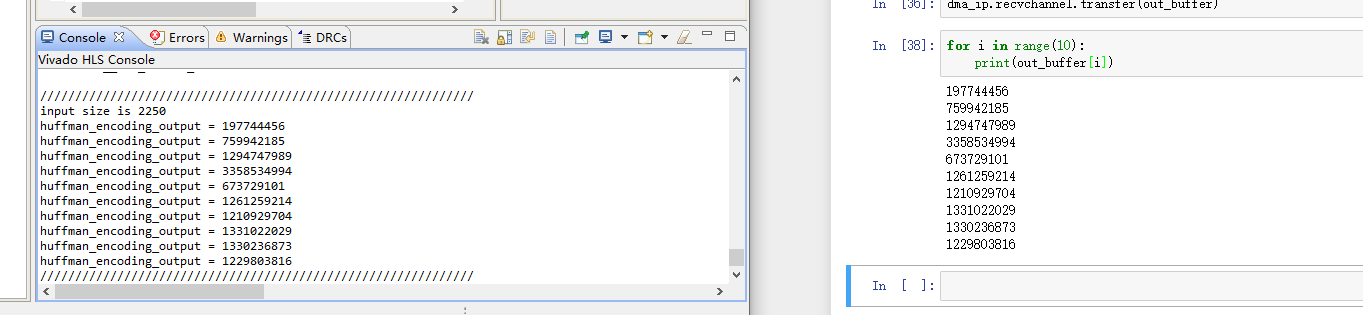 图 1
图 1
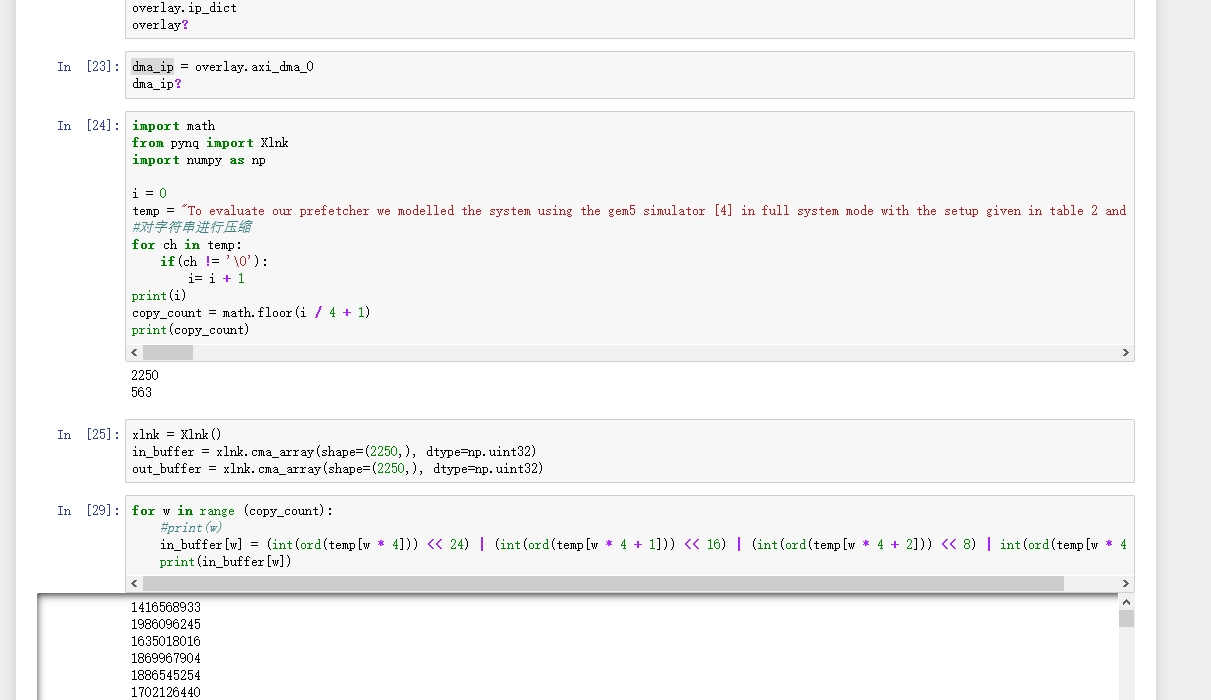 图2
图2
第二部分 系统组成及功能说明 /System Construction & Function Description
2.1 系统的功能实现
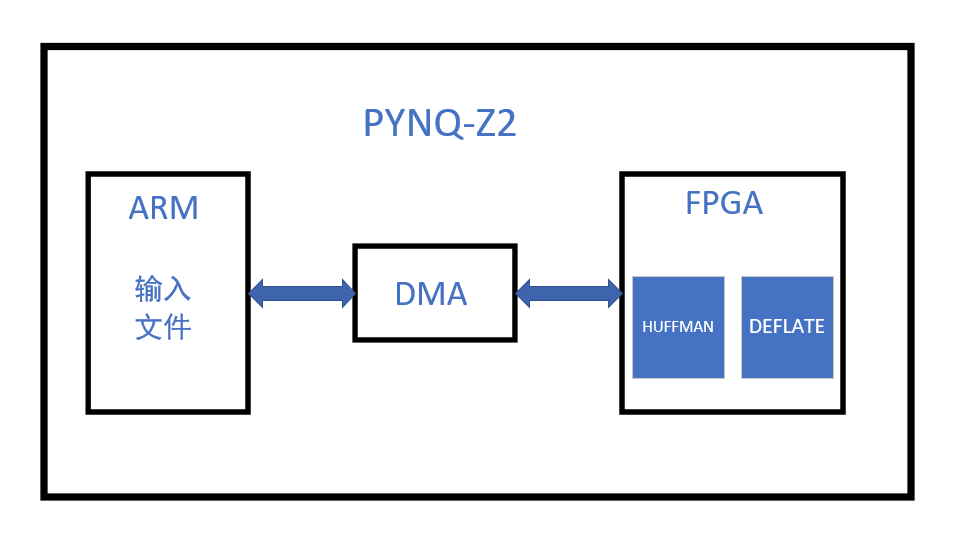
本设计中,在pynq-z2 FPGA平台上使用Gzip对文件进行了压缩算法的加速实现。整体分为两部分,硬件部分采用静态霍夫曼编码,使用deflate对文件进行压缩操作。Python模块将FPGA硬件的deflate输出进行封装,将其封装为gzip格式。
2.2 项目系统框图
系统结构框图如图3所示。
图3
2.3 gzip的基本组成
Gzip 压缩是广泛使用的数据压缩方案,核心是 Deflate算法,主要包括 LZ77 编码和哈夫曼编码两大部分。
2.3.1 gzip文件头的基本组成
文件头部分结构如图4:
 图4
图4
上面两个“+”之间的内容代表一个字节,所以上面除了MTIME使用四个字节之外,其他只占用一个字节。
ID1 和ID2(IDentification) :这两个字节用于标识gzip文件,其中,ID1 = 31(0x1f,�37),ID2 = 139(0x8b,213),如果判断某文件以这两个字节开头,那么可以初步认为这是gzip文件,但具体是不是,必须该文件格式完全符合gzip文件格式才行;
CM (CompressionMethod):该字段用于标识当前gzip压缩文件内部的压缩结果所使用的压缩方法,取值范围[0,8],其中,[0,7]保留,目前只用8,即gzip使用deflate压缩方法;
FLG (FLaGs):标记位,该标记位中的每一比特分别代表后面对应扩展位是否存在,各比特位含义不在此处列举;
MTIME (ModificationTIME):该字段给出了被压缩的原始文件最近被修改的时间。该时间使用Unix格式,即,自1970年1月1日0时起到现在的秒数。
XFL (eXtraFLags):该字段是用来记录gzip文件中所使用的压缩方法,由于当前gzip只使用一种压缩算法,即deflate,所以针对deflate,该字段有如下含义,
XFL= 2 – 压缩率最大但是压缩速度最慢(的那个压缩级别);
XFL= 4 – 最快的压缩(级别);
OS (OperatingSystem):该字段表示执行压缩操作的文件系统。该字段用于识别和确定确定文本文件的行结束标志。
2.3.2 gzip文件尾和文件体的基本组成
相比gzip文件头,gzip文件尾较简单,只由四个字节构成,结构如图5:
 图 5
图 5
CRC32 (Cyclic Redundancy Check):用标准循环冗余校验算法对原始数据进行计算的结果。
ISIZE (InputSIZE):将原始数据大小对2^32取模的结果。
上面已经将整个gzip文件的基本文件格式分析完毕,下面简单介绍gzip文件的文件体。该文件体主要与压缩算法deflate相关。因为只要用到deflate的文件格式,该部分都是一样的,比如gzip的文件体和PKzip的文件体“基本”是一样的,因为它们都使用deflate进行压缩。
2.4 DEFLATE 算法原理
DEFLATE 算法标准是由两个压缩算法联合构成的,压缩流程如6图所示,其中主要包含 LZ77 和哈夫曼编码。首先利用 LZ77 算法进行字典查找替代,消除重复信息,然后进行哈夫曼编码构造平均长度最短的压缩码流。
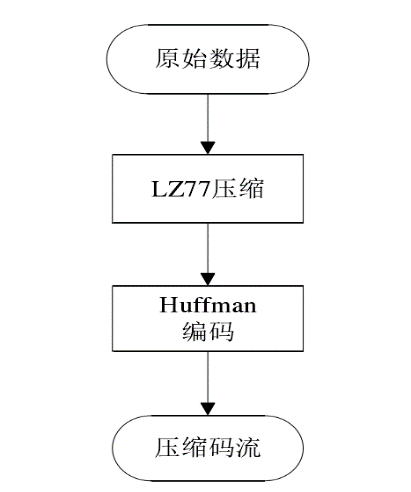 图6
图6
2.5 LZ77 算法
LZ77 算法是一种基于字典模型的压缩算法。DEFLATE 算法中用到的 LZ77 算法是在原始 LZ77 算法的基础上略加改进得到的,但算法基本思想保持不变。其基本原理为:将先输入的数据作为字典信息进行保存,利用数据中存在字符串重复带来的数据冗余性,根据字典中存储的历史数据对后续数据进行替换达到压缩的目的。
具体在 Gzip 压缩的参考软件代码 zlib 中实现 LZ77 算法的流程为:首先读入缓存窗口大小 CHUNK 的数据,其中窗口的大小与匹配最大距离 MAX_MATCH 有关;依次计算输入字符串的哈希值,将哈希值的作为字典地址的索引值,将字符串的位置信息依次存放在由哈希链表组成的字典中其哈希值对应的位置上;然后对当前的字符串根据索引值查找可能匹配的历史字符串并进行最长匹配查找,判断是否满足匹配条件,若满足则进行匹配对的替换;若不满足则按照原始字符串输出。对于 LZ77 压缩算法的实现关键点在于历史字符串的存储、当前字符串的匹配查找、以及最长匹配选择。
2.6 Huffman 编码
哈夫曼编码( Huffman coding )在数据压缩的分类中提到,是一种基于统计模型的压缩算法。其编码理论依据是统计符号出现的概率,对符号按照概率从小到大进行排序,将其中出现概率最小的符号分配最长的编码长度,按照这样的规则进行变长编码,达到平均编码长度最小。具体编码过程为:首先统计不同符号出现的概率,然后根据概率构建哈夫曼树,最后根据哈夫曼树得到每个符号的哈夫曼编码。具体步骤如下:
步骤 1:统计 n 个不同信源符号出现的概率;
步骤 2:将概率按照从大到小的顺序进行排列,并将其作为节点数为 1的子树;
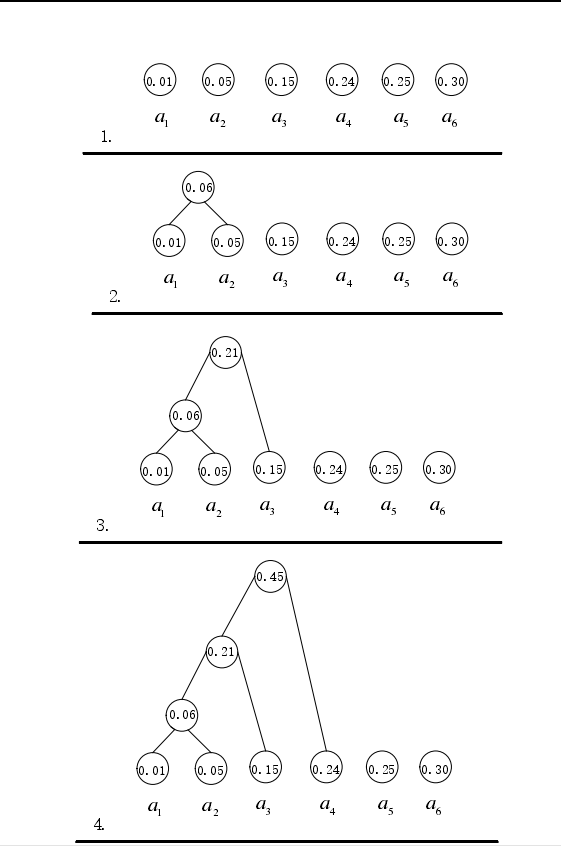 图7
图7
步骤 3:选出概率最小的两个信源符号所在的子树构成新的子树,并且新合成的子树概率为这两个信源符号的概率相加;
步骤 4:重复步骤 3,直到所有信源符号的所在子树均被加入到同一树中;
步骤 5. 对构建的树所有父节点的左结点标记为 0,右结点标记为 1;
步骤 6. 统计根节点到每个子节点的路径,按照步骤 5 中 0-1 标记的路径就是对应叶节点信源的哈夫曼编码。
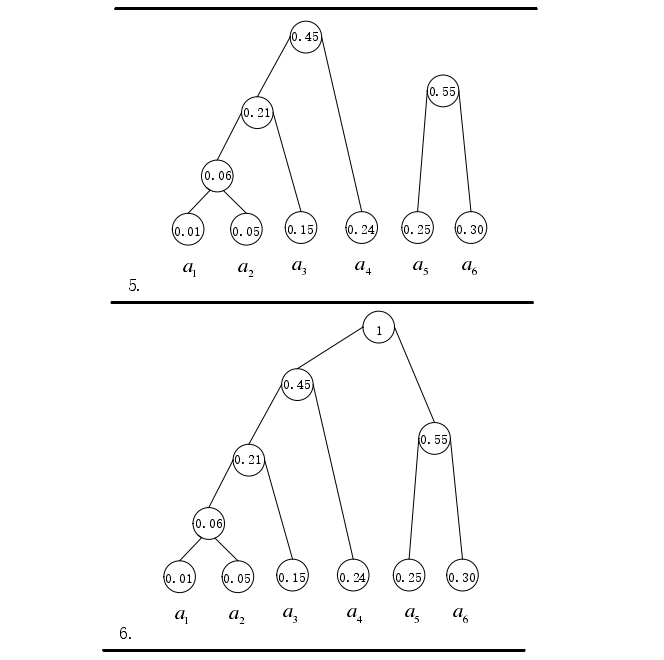 图8
图8
另外,在 Gzip 压缩中,哈夫曼编码的实现有两种:分别为静态哈夫曼编码和动态哈夫曼编码。其中静态哈夫曼编码不需要对编码的字符做频率统计,而是直接根据预先定义的编码规范表查找进行编码;似的,在解码的过程中也不需要统计频率而直接使用与编码一致的编码规范表进行解码。对于动态哈夫曼编码则遵循哈夫曼编码的原理,需要对出现的字符进行频率统计,生成哈夫曼树,再据此生成编码表进行编码。
在本设计中,我们采用静态哈夫曼编码来进行实现。
第三部分 完成情况及性能参数 /Final Design & Performance Parameters
整体功能已经实现。并具备一定的加速效果,相比纯arm进行压缩速度提高了1.6倍。Vivado硬件工程能够通过综合、应用、生成比特流。最后通过Jupyter Notebook在pynq z2平台上进行功能验证。具体展示如图9,左侧是在hls仿真是产生的结果,右侧是通过jupyter notebook在pynq z2上进行调试的结果,两者是一致的,压缩功能能够正常运行。
图9
图10,图11中,hls正常进行仿真,首先通过压缩算法对txt文件或字符串进行压缩,接着进行解压操作,将解压后的代码与源代码进行比较,如果结果一致,则能够验证压缩算法本身功能的准确性。
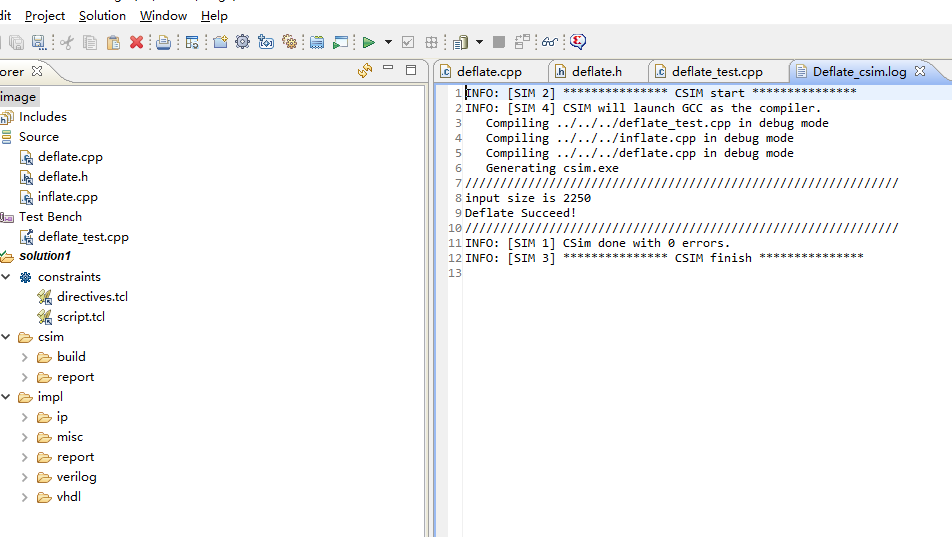 图10
图10
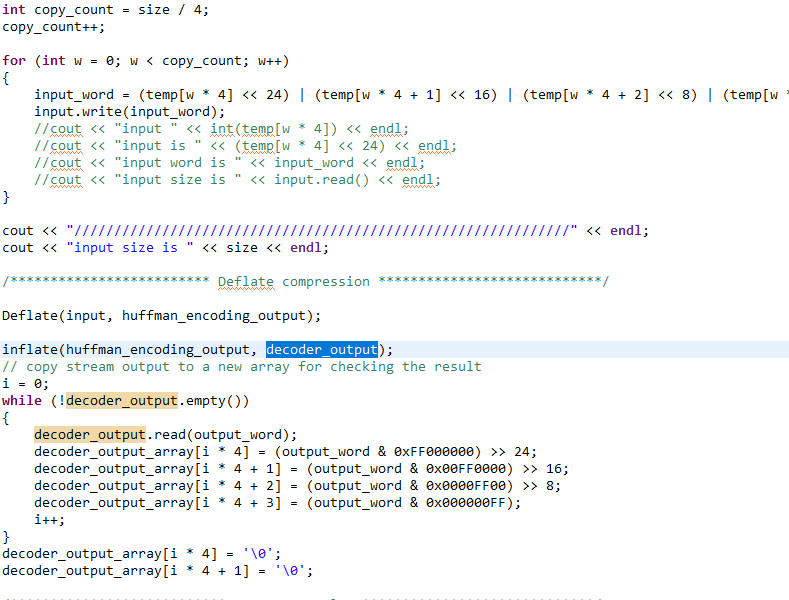 图11
图11
在图12,图13中,我们展示了部分压缩算法代码及优化指令,整体设计的源代码为github上的开源代码,在优化后我们外部的接口采用hls::stream的形式,内部使用到了pipeline,unroll等。
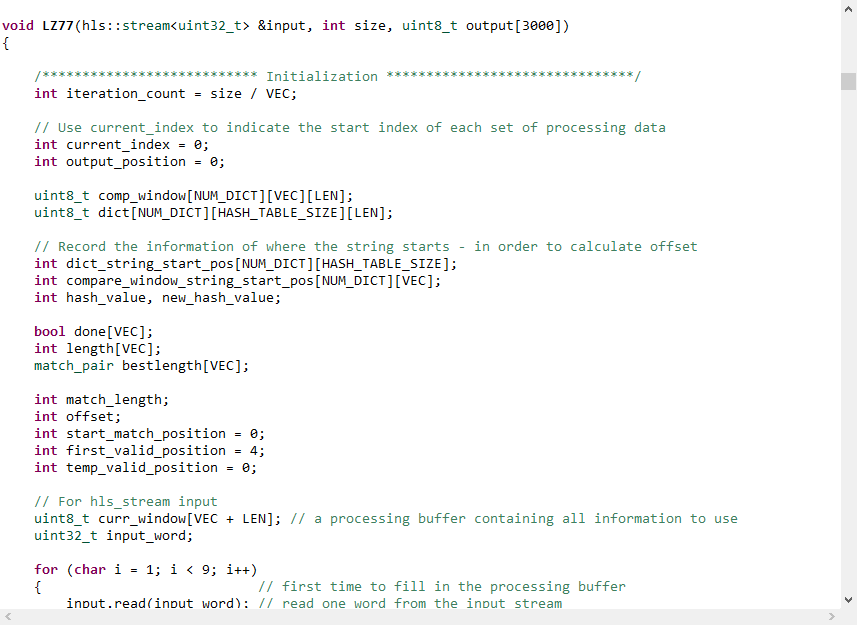 图12
图12
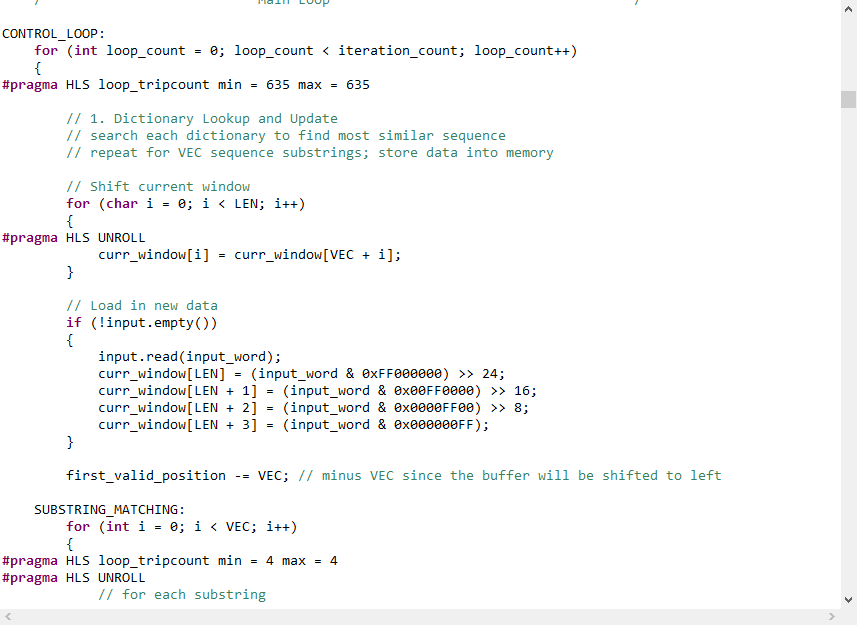 图 13
图 13
在图14,15中我们展示资源占比情况和时序分析,进行优化后实现了部分流水。
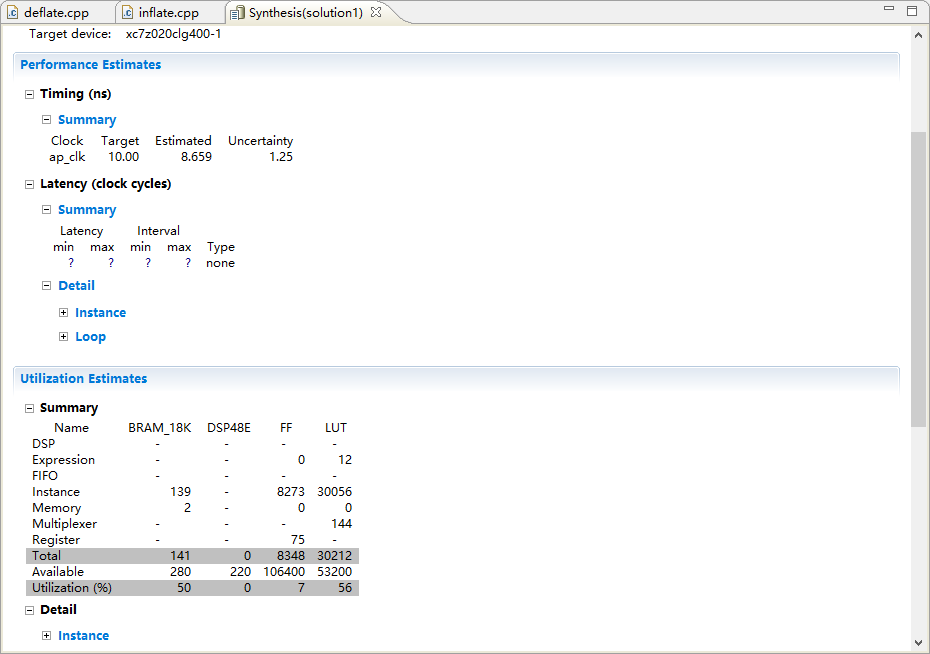 图14
图14
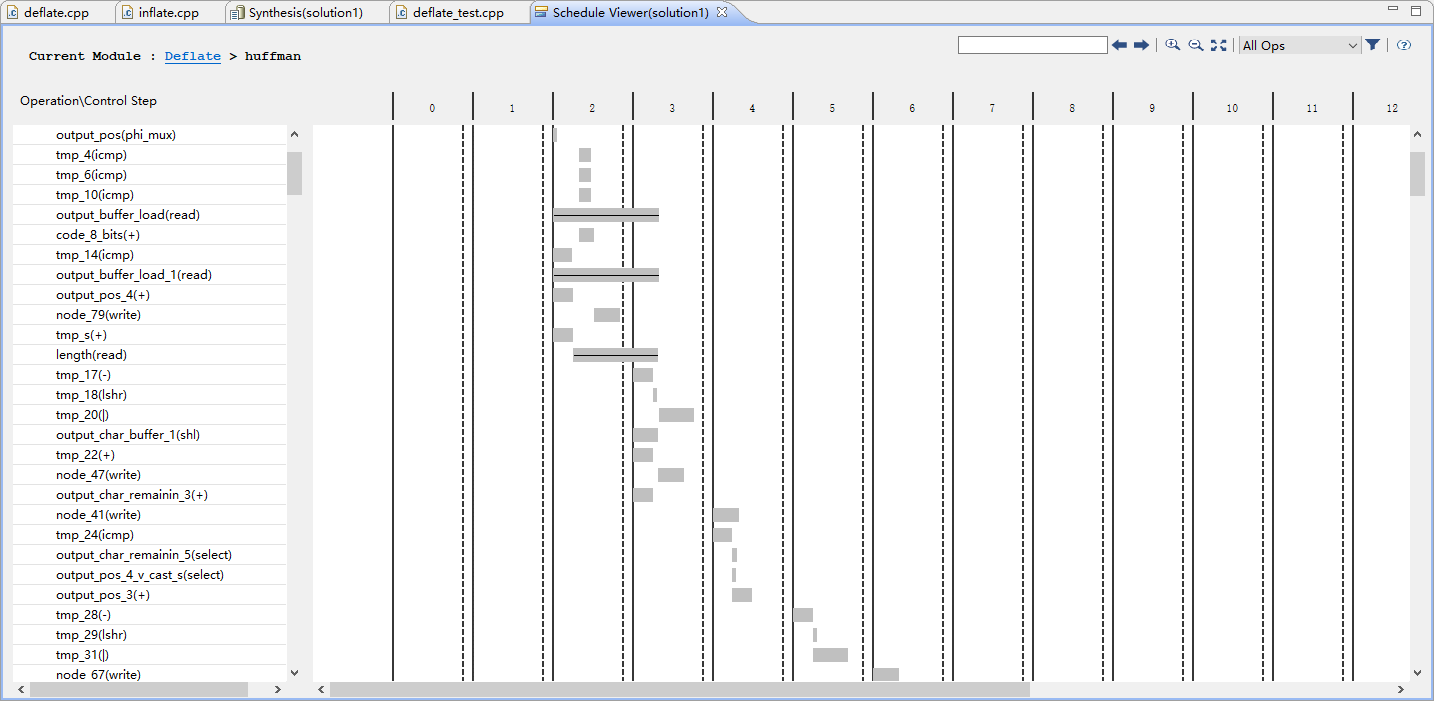 图15
图15
图16中,vivado电路设计图中hls生成的gzip ip核通过dma与ps端进行数据交互。
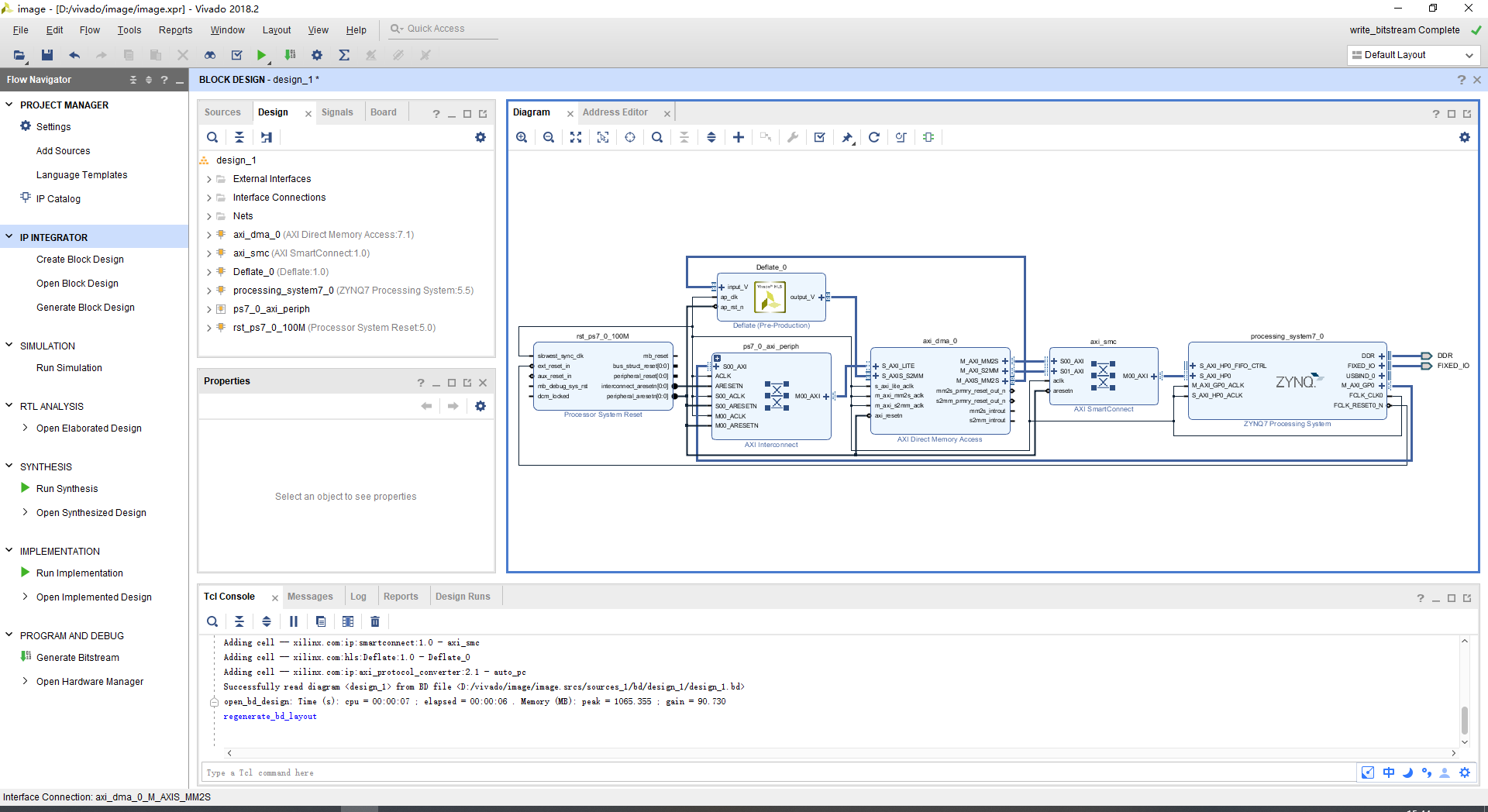 图16
图16
图17中,我们展示notebook部分调试代码,为了方便查看对部分输出结果进行输出,与HLS仿真结果进行对比发现结果正确,达到了最初的设计要求。
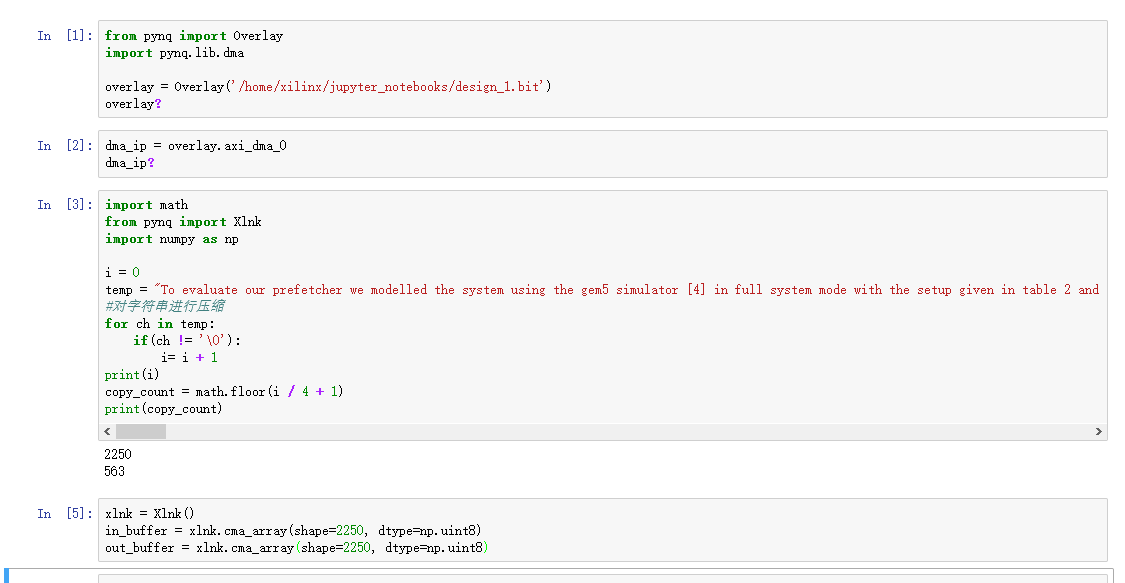
图17
完