昨天的股市属于芯片,科创50大涨3%创近三年半新高,芯片产业链集体走强,尤其是寒武纪早盘盘中大涨近14%,总市值跃居科创板头名,昨天的群里充满了寒王的欢乐段子。

背后的引爆点,一个是英伟达暂停了H20的生产。

另一个则是由于DeepDeek V3.1发布的官方留言:
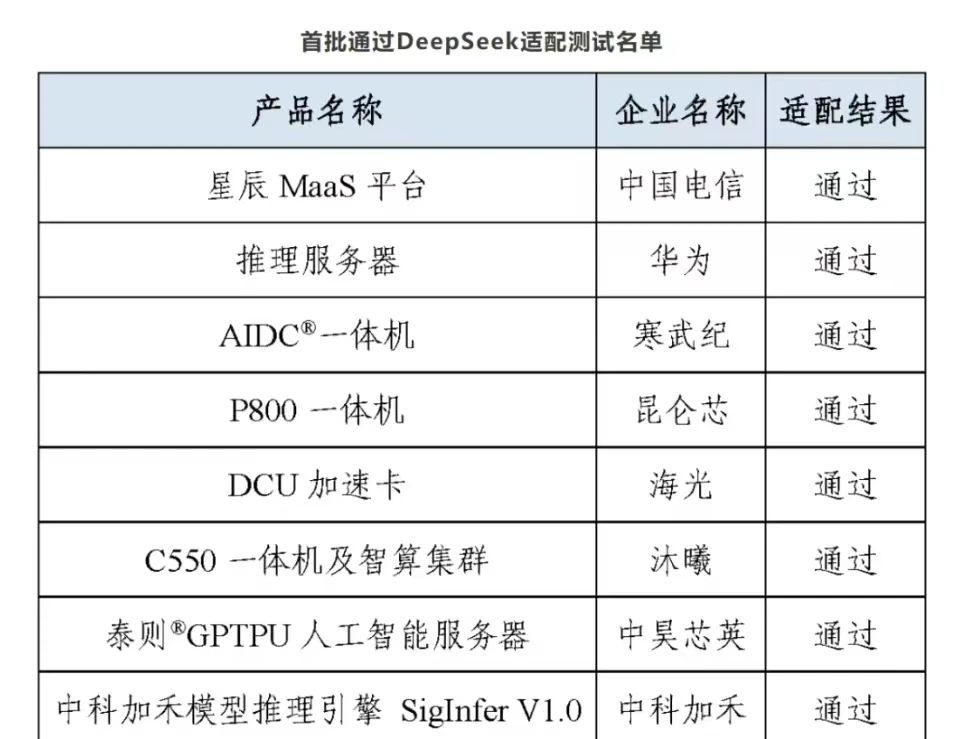
这代表了国产AI的软件和硬件正在形成闭环,减少对国外算力软硬件的依赖。目前已经通过DeepSeek适配测试的国产硬件包括:
从改革开放以来,我们很多行业走过了从“Copy to China”阶段,到“Born Global”阶段,甚至达到“Rule Making”的水平。
以我国互联网的发展为借鉴,我们诞生了很多Copy to China 的典型案例,以下是一些代表公司。
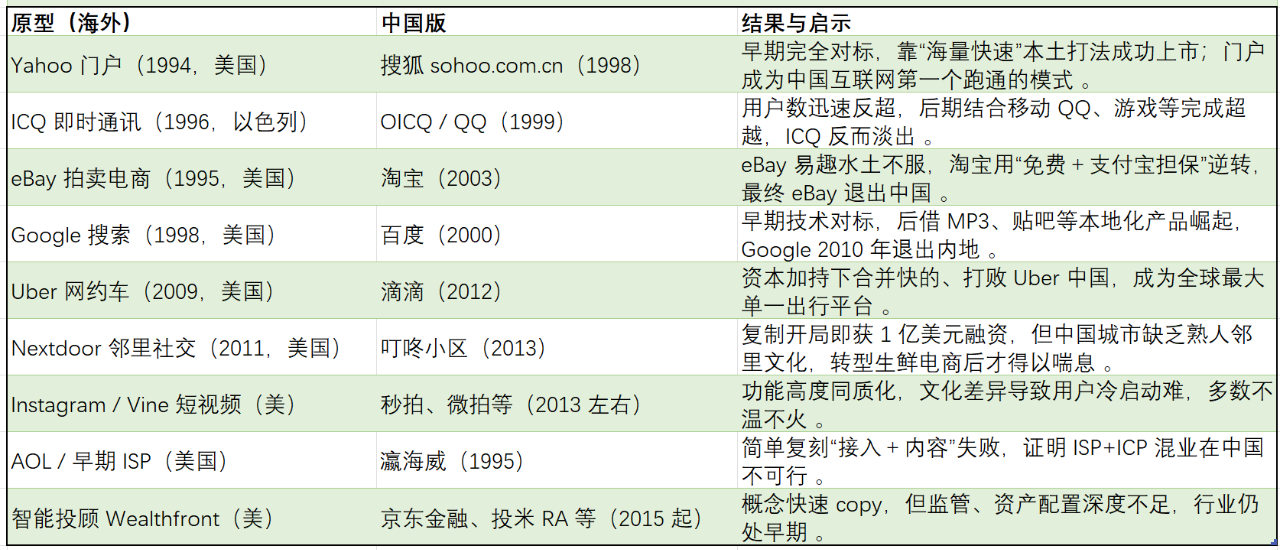
从时间轴看,1998-2005 年(门户、搜索、电商、社交)是 Copy to China 的第一波高峰;2010-2015 年(网约车、团购、短视频、O2O)为第二波;2015 年后进入“Copy from China”反向输出阶段 。
现在中国互联网“反向输出”已经从单点试水变成系统性的“模式出海”,逐渐把我们的本土化创新卖到了全世界。
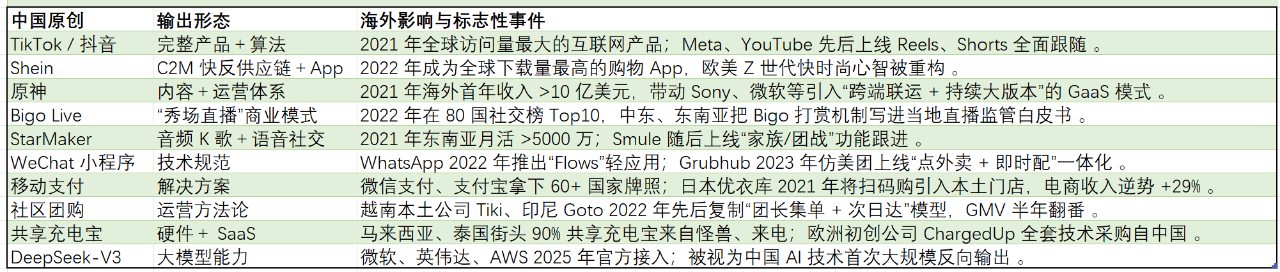
从以上的案例来分析,2016 年前更多是“Copy to China”,2017-2020 年开始“Born Global”(Shein、TikTok),2021 年后进入“Rule Making”——中国模式变成海外监管和竞品的参照系。从产品 → 商业模式 → 技术规范 → 产业标准,层层递进;移动支付、小程序、OTA 已上升到“标准输出”阶段。
回到半导体行业,我们现在处于什么阶段呢?
半导体行业整体上已经脱离Copy to China阶段,但并未全面进入反向输出,而是处于局部突破+加速国产替代的过渡带。
把现状拆成 4 个维度看会更清楚:
1. 技术层次——“低端已平替,高端仍卡脖子”
• 28nm 及以上成熟制程:设备国产化率 >50%,材料、封测环节基本可自主循环 。
• 7nm 及以下先进制程:EUV 光刻机、高阶 EDA、ArFi 光刻胶仍被“卡脖子”,只能“绕道”DUV + 多重曝光实现有限量产,性能和良率落后台积电 2-3 代 。
2. 产业链角色——“从代工学习者到生态共建者”
• 设计:海思、寒武纪、平头哥的 CPU/GPU/AI 芯片已能与英伟达、高通“并跑”,但制造环节被锁在 7nm 天花板 。
• 制造:中芯国际、长江存储等不再只是“学做代工”,而是牵头与设备、材料厂联合研发工艺标准,角色由“Copy”转向“Co-define” 。
3. 商业模式——“内需替代为主,出口输出刚起步”
• 成熟制程产能大规模扩张,2025 年全球 28 nm 以上新增产能 40% 以上落地中国,主要满足国产替代需求 。
• 设备、材料开始小批量出海:北方华创刻蚀机、中微 MOCVD 已进入东南亚、欧洲二线晶圆厂,但尚未形成“反向输出”的规模效应 。
4. 竞争范式——“政策-市场双轮驱动” vs “技术封锁”
• 大基金三期+地方政府基金 2025 年预计再投 3000 亿元,资本密度全球罕见 。
• 美国主导的出口管制反而加速了国产供应链闭环,“被逼出来的创新”取代了早年的“Copy”。
因此,今天的中国半导体:
• 已经摆脱“简单复制”阶段——低端环节可完全自给,高端环节用架构、封装、系统级创新“曲线救国”。
• 尚未到“反向输出”阶段——除少量设备、材料外,尚未像 TikTok/Shein 那样反向定义全球标准。
• 可以定义为“自主可控 2.0”:一边补足短板,一边把成熟产能和特色工艺向一带一路国家扩散,为下一轮“Made in China, Defined by China”打基础。
我让Kimi分析了中美在半导体和AI领域的对标公司。
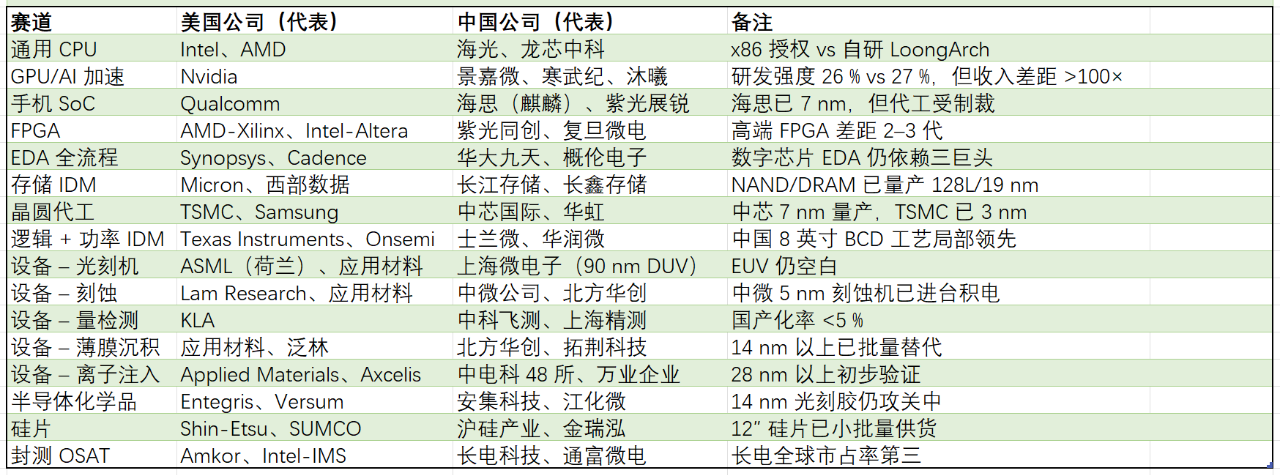
中美半导体“同类打擂”清单:
(按“美国公司 → 中国公司 → 主要对标赛道”排列)
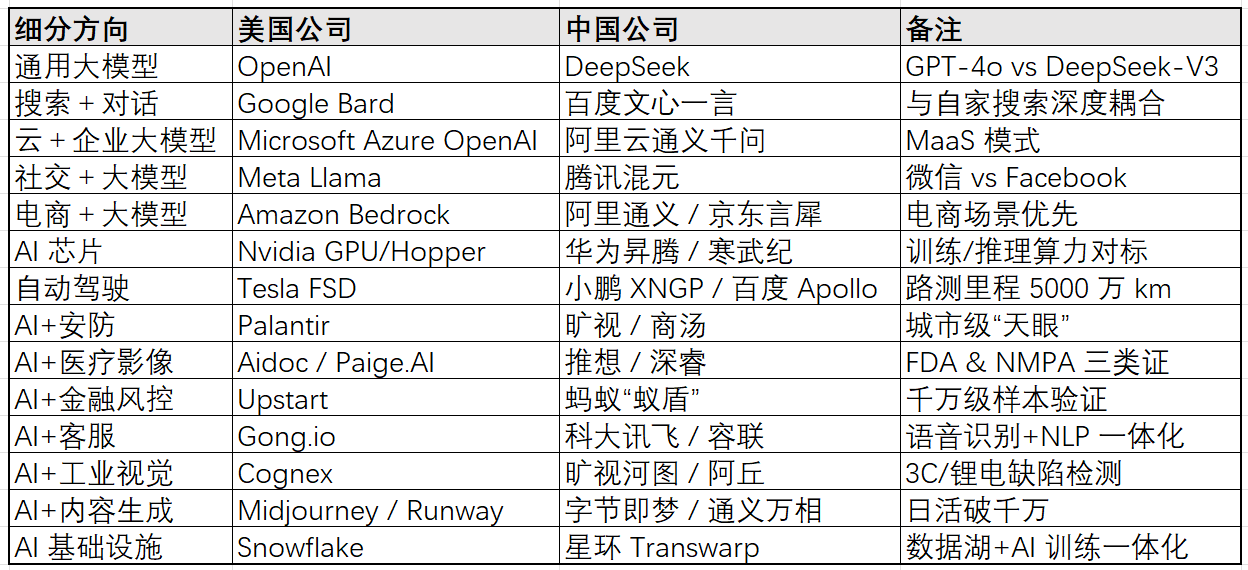
中美人工智能“同赛道对标”速览:
(按“美国公司 → 中国公司 → 主要对标方向”排列)
我国在“AI+芯片”这条赛道,已经形成了一条“可自我循环的国产替代闭环”,但高端训练算力仍被EUV 光刻机与先进 IP 掣肘,所以目前只是“结构闭环”而非“全自主闭环”。
1. 低端/推理市场已闭环
• 14nm及以上制程的推理芯片(华为昇腾、寒武纪、海光)在 2025 年拿下国内 AI 服务器约40% 市场份额。
• 中芯国际14nm 产能已突破 20 万片/年,良率 99.8%,足够喂饱推理市场。
• DeepSeek、通义千问、讯飞星火等主流大模型都完成了对昇腾、寒武纪的原生适配,“国产模型+国产算力”在政务、金融、医疗等行业批量落地。
2. 高端/训练市场半闭环
• 7nm工艺已“风险量产”,但EUV 仍缺位,需靠 DUV 多次曝光,成本比台积电高、良率低。
• 新一代昇腾、思元通过 Chiplet 把算力做到H100的80%左右,已拿到字节跳动、阿里部分订单,但单卡功耗和互联带宽仍落后一代。
• 训练框架(MindSpore、Paddle、OneFlow)已能跑通千亿级模型,但 GPU CUDA 生态迁移成本仍高。
3. 设备/材料/EDA 仍是瓶颈
• 光刻机:上海微电子DUV 待验证。
• 刻蚀/薄膜:北方华创、中微 5 nm 设备已进中芯、台积电,国产设备覆盖率 > 50 %。
• EDA:华大九天实现 7nm数字全流程,但先进工艺PDK仍依赖 Synopsys/Cadence。
总之,推理侧闭环已跑通,训练侧闭环“只差光刻机”。再给中国 2–3 年时间,如果 7nm 产能顺利爬坡、EUV 取得突破,这条 AI 芯片国产替代链就能真正“闭环成环”。
<