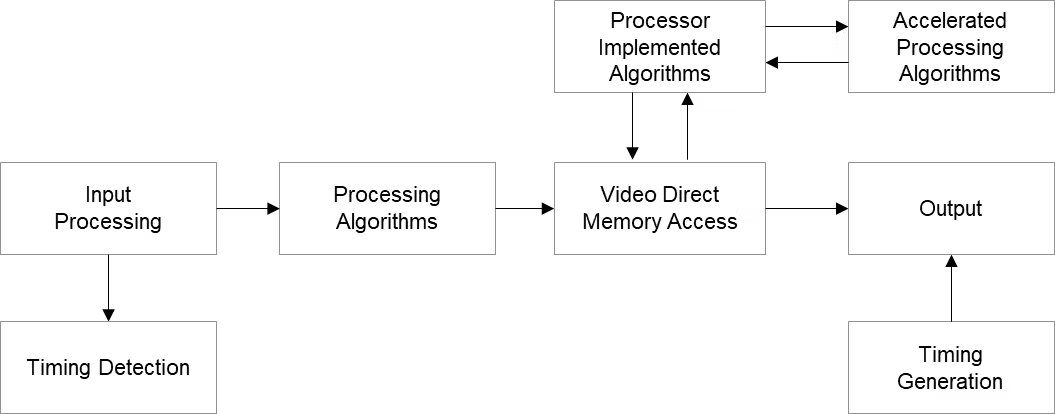
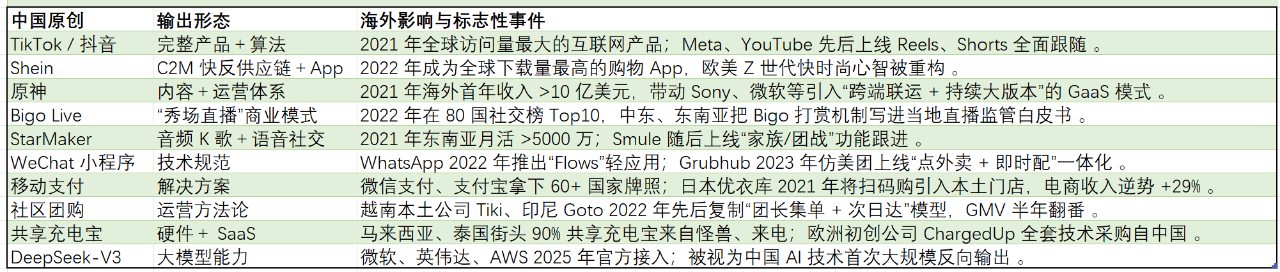
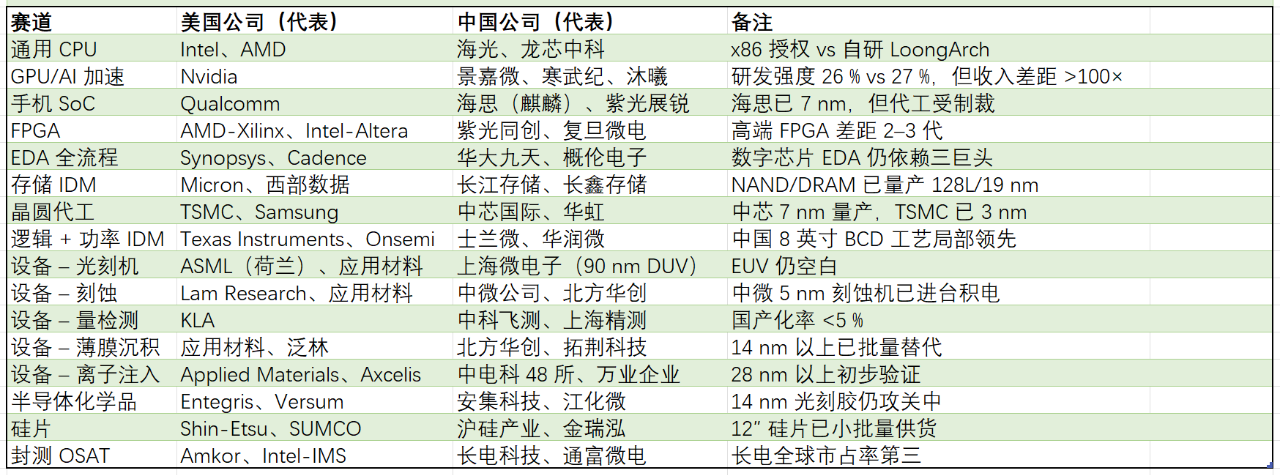
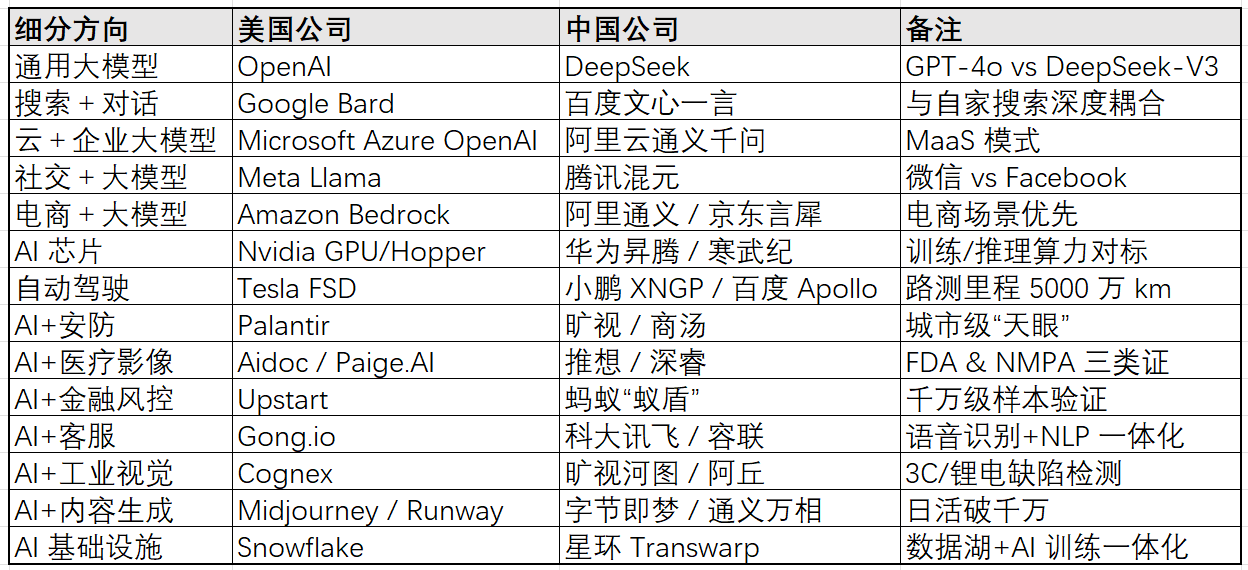
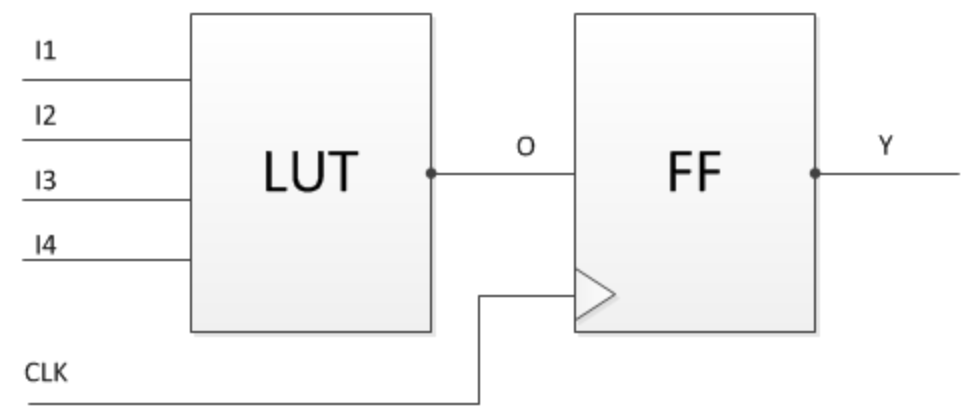
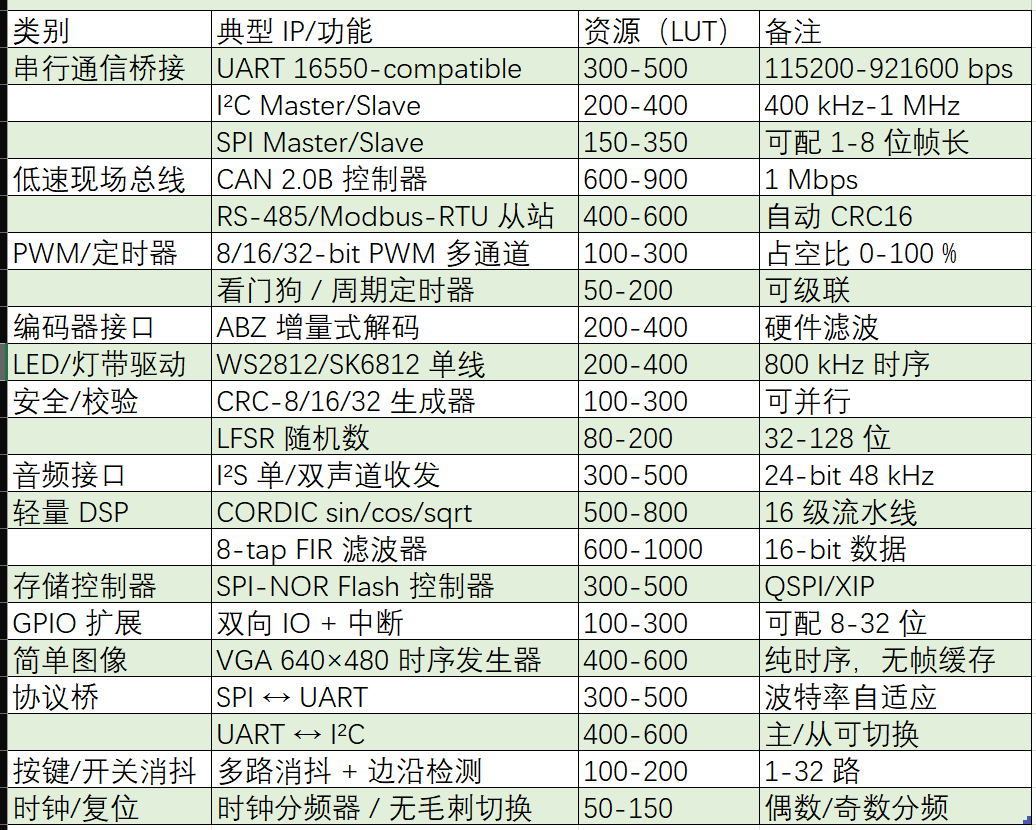
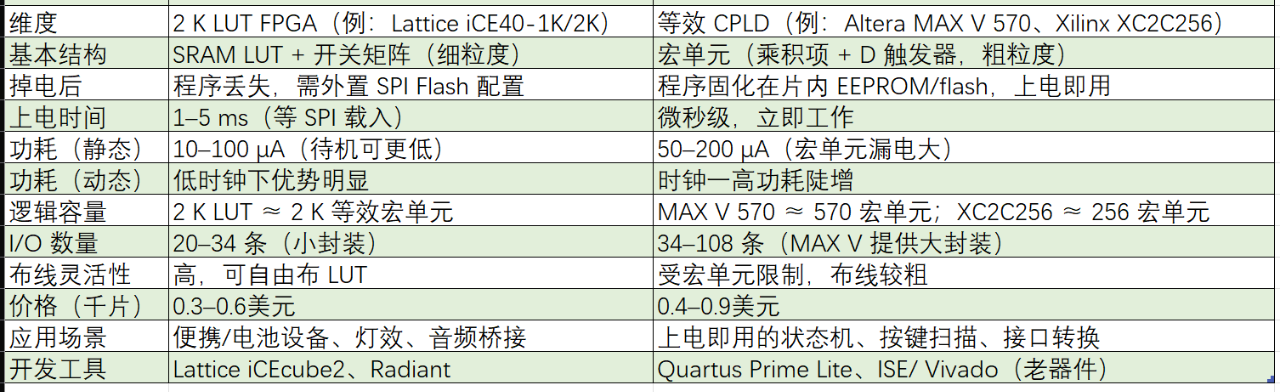
内卷的极致状态是怎么样的?最近看到O大的一篇旧文,讲述了他在大宗商品市场的经历:
他介绍完油的生产过程之后,他问全班一个问题,“如果你是一个炼油厂的老板,不管你在西伯利亚,北海,还是英国,你要去期货交易所报价自己的商品,你要怎么报价?
然后他一个一个问过来,有人说用均价,有人说用共识预期价格,有人说比之前报价的人低一点点。
那哥们说都不对,你有且只有一个选择,就是报价你的短期现金成本,short term cash cost。
然后我们都不明白,全班都很默然,然后他非常诡异地笑着和我们说,这就是大宗商品市场残酷的地方。他解释说,在一个同质化竞争,没有品牌溢价的市场里面,你唯一能做的就是尽可能降低自己的生产成本,然后希望去卷死对手,别无他法。所以你 甚至不能报价全成本(All in sustaining Cost),因为这里面包括了折旧和摊销,如果你这样报价,你可能会被一个忍受短期亏损,决定勒紧裤腰带两年然后自杀式报价的对手干掉,在那两年里面你觉得他在自杀,而两年后挂掉的反而是你。
最后我记得他的总结,大意是:远见在一个残酷竞争的同质化市场中不值钱,每个人都是争取在明天能活下来,然后明天的明天能活下来,然后如果运气好的话可以迎来一个真的明天。
他说以前生意最好的时候,他要招十几个工人,现在根据他的经验,他可能需要降低一些员工的数量,然后他也觉得如果需求不能好起来,那么后面的竞争会很激烈,他需要控本增效,希望用自己的经验和十几年的口碑活下来。
同质化竞争,只有一个活下来的方法就是降低短期成本。然后活下来的人最后再把所有亏掉的钱赚回来,而没有活下来的人就成为了故事里面的遗憾。
以上的故事总结下来,在完全同质化且需求短期刚性的市场里,囚徒困境把理性决策者逼向“现金成本自杀式报价”;而行业的长期利润只能靠“让对手先死”来实现——这就是所谓“大宗商品市场残酷的地方”。
把“报价只能等于短期现金成本”这个逻辑套到内卷行业,关键看四个条件:
1. 产品高度同质化,用户几乎只看价格
2. 产能退出壁垒低(或资金链脆弱),谁先断现金流谁先出局
3. 需求侧短期刚性,谁先涨价谁先丢单
4. 重复博弈:只要熬死对手,后面就能把亏掉的钱赚回来
满足这四条的行业,就会出现典型的“现金成本报价—极限压缩—剩者为王”内卷路径。现实中大体有三类:
一、大宗原材料与上游制造
· 钢铁(螺纹钢、热卷)
· 炼油、PTA、乙烯、纯碱、玻璃
· 硅料、锂盐、镍、钴——新能源周期里的典型“现金成本血战”
这些行业的产能在金融周期里被“超前建设”,一旦需求减速,价格直接打到可变成本,高折旧的新产能反而最先被拖死(2023 年的硅料、2024 年的锂盐都在重演)。
二、电子与半导体里的“标品”
· 存储芯片(DRAM、NAND)
· 面板(LCD、LED 芯片)
· 光伏组件、电池片
技术节点一旦标准化,品牌溢价瞬间归零,报价只看“现金成本+折旧忍耐度”。存储芯片每 3~4 年一次“自杀式杀价”,最后由三星、SK 海力士等现金流最厚的玩家把亏损再赚回来。
三、互联网与服务业的“流量标品”
· 网约车、外卖(运力端)
· 社区团购、共享充电宝
· OTA 的机票、酒店标品
· 直播电商的“白牌工厂货”
这些行业把“产能”换成了“司机/骑手/团长/机酒库存”,退出壁垒看似低,但平台通过补贴把“现金流”变成“流量现金成本”。谁先没钱补贴谁先掉单量,剩下来的平台再把份额变现。2021 年社区团购的“1 分钱买菜”就是典型“现金成本报价”。
不适用或弱适用的行业
· 需要强品牌或体验差异化的:白酒、化妆品、奢侈品
· 高研发迭代、专利壁垒深的:创新药、GPU、先进制程晶圆
· 政策强监管、退出门槛高的:银行、保险、公用事业
凡是你能说出“谁家便宜就买谁”且产能能快速扩张或退出的行业,都可能被这条逻辑锁死。那么我们身处的MCU行业,是否适用这个逻辑呢?
答案显然是不适用的,至少远没到“只能报短期现金成本”的极端境地。原因有三点:
1. 产品并非标品
MCU 有 8/16/32 位、主频、Flash/RAM、外设组合、温度等级、功耗、封装等几十个维度,同一颗料号往往对应多家客户的定制固件。用户要的不只是“便宜 1 分钱”,而是“刚好满足我板子上的 5 路 UART + 2 路 CAN + 低功耗 3 µA”,同质化程度远低于大宗 DRAM 或螺纹钢。
2. 客户锁定效应强
– 代码重写的迁移成本(外设库、引脚兼容性、IDE 生态)远高于换一袋水泥或换一块光伏板。
– 车规、工规要过 AEC-Q100、IEC61508 认证,周期 1~2 年,形成“认证壁垒”。
– 大客户还要签 5~10 年长期供货协议(LTSA),价格里包含了“供应安全溢价”。
这些因素让厂商敢在报价里保留折旧和毛利,而不至于被“自杀式对手”一夜踢出局。
3. 产能退出/扩张弹性差
MCU 用 40 nm~90 nm 的成熟节点,但这些产线同时跑 Nor Flash、PMIC、CIS 等十几种产品,产能切换需要 mask set 和良率爬坡,不能像炼油厂“今天开、明天关”。因此即使短期需求下滑,也很少出现“大家一起把价格打到现金可变成本”的踩踏。
现实数据也印证了这一点:
2023 年全球 MCU ASP 下滑约 15 %,但头部厂商(ST、NXP、Microchip、Infineon)毛利率仍保持在 45 %~55 %,远高于硅料、存储芯片的 10 %~20 % 甚至亏损区间。大家拼的是“产品组合 + 生态 + 长期供货”,而不是“谁能把固定成本全部牺牲掉”。
所以,兼容 MCU 行业是“差异化红海”而非“纯价格战红海”。你可以看到局部杀价(比如 8 位消费级小厂互砍),但行业整体仍保留品牌、认证、生态和长期协议带来的溢价空间,因此远不到“只能报短期现金成本”的残酷逻辑。
具体到MCU的各个细分赛道,其内卷程度也是冷热不均的。
8位MCU
8 位 MCU 已经“红海到发紫”,价格普遍低于 0.2 USD,但远未到“只能报短期现金成本”的极端——各家还能靠“外设组合 + 车规/工规认证 + 长寿命供货”保留一点毛利,整体属于“深红海”而非“血海”。
1. 价格跌幅:脚踝斩
• 2020 年主流 PIC/AVR 仍卖 0.35–0.5 USD;
• 2024 年国产兼容型号(Padauk、赛元、晟矽、中颖)渠道价 0.12–0.18 USD,跌幅 60–70 %;
• 最低端 OTP 版本杀到 0.06 USD(Padauk PMS150C 10 k+ 价格)。
2. 玩家密度:30+ 家混战
Global top:Microchip(PIC/AVR)、瑞萨(RL78/78K)、ST(STM8)、NXP(S08)、英飞凌(XC800)等仍占高端。
中国本土:赛元、中颖、晟矽、芯海、东软载波、灵动微、汇春、赛腾微、赛芯、航顺等 >20 家,每家都有 10 余颗 Pin-to-Pin 兼容料号。
3. 技术护城河:只剩“外设+认证”
• 通用型(GPIO+ADC+PWM)已完全同质;
• 带 12-bit ADC、CAN-FD、LIN、LCD Driver、车规 AEC-Q100 Grade 1 的 8 位单片机仍能卖 0.4–0.6 USD;
• 工业级 ‑40 ℃~105 ℃、15 年供货承诺的料号,价格可再溢价 30–50 %。
4. 需求侧:总量稳、结构分化
• 全球 2024 年市场规模 544 亿元人民币,未来六年 CAGR 仅 4.8 %;
• 家电、玩具、低端电动工具、汽车节点、智能卡仍是主战场;
• 高端 8 位(带 CAN/LIN)在车身/照明节点继续增长,低端 OTP 市场因 32 位 M0 挤压呈萎缩。
8 位 MCU 的“深红海”特征:
– 通用型价格已逼近晶圆级现金成本,但车规/工规/长寿命料号仍留 30–50 % 溢价;
– 市场总量稳定且分散,玩家超过 30 家,价格战常态化,却未到“集体跳楼”阶段;
– 未来三年,高端认证 8 位与超低价 OTP 将两极分化,中间档会被 32 位 M0 进一步蚕食。
M0级MCU
32 位 M0 级 MCU 已经进入“价格脚踝斩”的残酷内卷阶段,但还没到“只能报短期现金成本”的纯大宗逻辑——因为仍有生态、认证和供货安全三层差异化护城河,只是水位越来越浅。
1. 价格
• 2015 年一颗 32 位 M0 还能卖 3~4 元人民币,2024 年渠道现货最低已杀到 0.4~0.5 元,跌幅接近 90 %。
• TI 2024 年在车规项目直接把 M0+ 系列报到 0.6 USD,国产厂商 1 USD 都接不住。
• 消费级 STM32F030 等通用料号常年 3~4 元横盘,但国产 Pin-to-Pin 替代件已做到 1 元以内。
2. 玩家数量
• 公开叫得出名字的国产 M0 级厂商 >30 家,兆易、航顺、华大、中微、国民技术、芯海、沁恒……每家都至少 3–5 条 Pin-to-Pin 对标线。
• 原厂+代理+贸易商三线并行,渠道库存常年 3–6 个月,价格踩踏频繁。
3. 产能与工艺
• 8 英寸 eFlash 工艺已经成熟,2024 年起多家转向 12 英寸 55/40 nm,进一步缩小 die size,单颗 wafer 成本再降 15–20 %。
• 晶圆厂产能释放+砍单潮,使得“晶圆代工费”不再是护城河。
4. 差异化护城河还剩多少
• 生态:STM32Cube、Keil/IAR Pack、社区教程仍是新人首选,国产虽兼容但生态黏性略弱。
• 认证:车规 AEC-Q100、工业级 105 ℃/125 ℃ 仍是硬门槛,能把价格托在 0.6–1 USD 区间。
• 供货安全:长协+库存+多晶圆厂备份,大客户愿意付 10–20 % 溢价。
因此如果你做的是消费级、无认证、Pin-to-Pin 通用的 32 位 M0,那已经是红海中的红海,价格战随时击穿现金成本; 一旦加上车规、工规、低功耗、无线协议栈或安全加密,就仍能保留 30–50 % 溢价,暂时脱离“纯内卷”轨道。
M3/M4级MCU
M3 已经“红海化”;M4 正在“浅红→深红”过渡,高端型号仍靠附加价值缓降,但通用型离“脚踝斩”只差一年。
1. 价格曲线
• M3(主频 72–120 MHz,无 FPU):
2020 年渠道价 ≈ 2.5 USD;2024 年国产 Pin-to-Pin 最低杀到 0.7 USD,跌幅 ≈ 70 %,与当年 STM32F103 现货价 1.2 USD 相比已倒挂 40 %。
• M4(主频 120–240 MHz,带 DSP/FPU):
2020 年通用型 F4xx 系列 3–4 USD;2024 年国产 AT32F407、GD32F407 已降到 1.2–1.5 USD,跌幅 ≈ 60 %。
带高速 USB、以太网、CAN-FD 的“高配”M4(如航顺 HK32F4、小华 HC32F4A0)仍能守住 2–3 USD,溢价 50–100 %。
2. 玩家密度
• 公开量产 M3 的本土厂商 ≥ 25 家,兆易、航顺、中科芯、雅特力、极海、国民技术全部有 Pin-to-Pin 兼容料号。
• 量产 M4 的目前约 15 家,其中 9 家 2024 年已发布 ≥ 240 MHz、带 Ethernet/USB-HS 的高集成型号。
→ M3 出现“20 家抢 1 个插座”,M4 目前还是“10 家抢 3 个插座”。
3. 技术护城河
• M3:外设差异小,主流封装 LQFP-48/64 已标准化,软件生态 90 % 以上兼容 STM32,导致“谁便宜谁上位”。
• M4:高速接口(USB-HS、Ethernet MAC、CAN-FD)、大容量 SRAM/Flash、硬件加密、电机控制协处理器仍能做差异化;车规 AEC-Q100、工业 125 ℃ 认证可再抬 30–50 % 价格。
4. 产能 & 工艺
• 2024 年起 55/40 nm 12 寸线对 M3/M4 全面开放,die cost 再降 20 %;
• 8 寸线库存高企,M3 通用料号现货 6–10 周即可交,进一步压价;
• 高集成 M4 仍需 40 nm + 高速模拟 IP(USB-PHY、Ethernet-PHY),短期难以大规模杀价。
M3 已陷入“价格踩踏 + 渠道踩踏”的深红海,基本符合“现金成本报价”前的最后一道门槛; M4 的通用型(仅 FPU+DSP,无外设升级)正在复制 M3 的路径,预计 2025–2026 年也会跌到 1 USD 以下; 带高速接口、车规/工规认证的“高配”M4 还能维持 2–3 USD,暂时留在“差异化红海”区间,但窗口期仅剩 1–2 年。
M4级以上MCU
M4 以上(M7、M33、M55 等)暂时处于“浅红”状态——价格已松动,但远未像 M0/M3/M4 那样打到现金成本;真正的护城河是高速外设、车规/工业认证、功能安全和生态锁定,三到五年内不会演变成纯内卷。
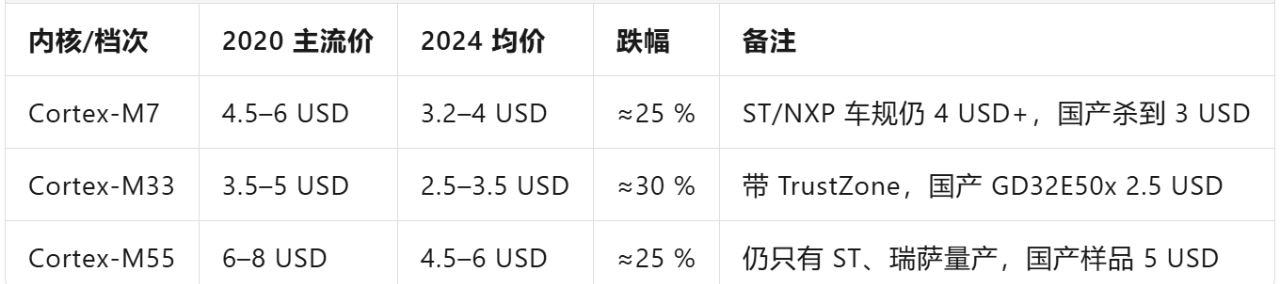
1. 价格与跌幅(对比 2020 → 2024)
→ 跌幅明显小于 M0/M3/M4 的 60–90 %。
2. 玩家与产能
• 全球能量产 M7/M33/M55 的厂商 < 10 家;大陆能量产 M7 的只有兆易、航顺、极海、国民技术 4 家,真正能量产 M33/M55 的目前 0 家(样品阶段)。
• 工艺集中在 40 nm eFlash,12 寸线产能被车规/工业长期协议锁定,短期不会大放量。
→ 供给端天然寡头,抑制踩踏式杀价。
3. 差异化护城河
• 外设复杂度:480 Mbps USB-HS、2-port Gigabit Ethernet、CAN-FD × 8、SDIO 3.0、LCD-TFT、2D-GFX、硬件加密引擎——任何一项的模拟/PHY IP 都不是 6–9 个月就能“抄”出来的。
• 认证:车规 AEC-Q100 Grade1/2、ISO 26262 ASIL-B/C、工业 SIL-2,验证周期 18–30 个月;客户不愿冒险换料,价格容忍度高。
• 生态:ST STM32Cube、NXP MCUXpresso、瑞萨 FSP 提供完整驱动、安全库、OTA 方案;国产厂商仍在追赶。
4. 需求侧
• 汽车域控(网关、车身、电池管理 BMS)、工业伺服、高端 PLC、图形仪表盘、AI 边缘节点对主频 200–400 MHz、Flash 1–2 MB、SRAM 512 KB 以上的 MCU 需求年增 15 %。
• 2024 年缺的不是“核”,而是“带高速接口 + 功能安全 + 十年供货保证”的组合拳。
M4 以上 MCU 仍处在“技术-认证-生态”三重壁垒保护的蓝-红过渡带:
• 2024–2025 年价格会继续温和下探 15–25 %;
• 2026 以后若国产厂商完成车规认证和大批量产能爬坡,才可能向 M4 的深红海靠拢。
因此目前谈“内卷到现金成本”为时尚早,属于“蓝海末班车”或“浅红窗口期”。
<